AI & ML · Research
ZeroDayBench: Benchmarking LLM Agents for Security Flaw Patching Challenges
Explore ZeroDayBench—A new benchmark testing the efficacy of leading LLM agents in discovering and patching unseen security vulnerabilities.

Anurag Verma
10 min read

Sponsored
Even the most advanced AI models (GPT-5.2, Claude Sonnet 4.5, and Grok 4.1) failed to patch 73% of critical security vulnerabilities in a new benchmark test. The ZeroDayBench evaluation reveals a gap between AI hype and cybersecurity reality, forcing us to confront uncomfortable truths about autonomous defense systems.
While enterprise security teams increasingly deploy AI-powered tools to combat sophisticated cyber threats, the harsh reality exposed by ZeroDayBench suggests we’re placing dangerous levels of trust in systems that fundamentally misunderstand security contexts. This benchmark, evaluating 22 novel critical security vulnerabilities across different attack vectors, marks a turning point in our understanding of AI’s current limitations in cybersecurity applications.
Understanding ZeroDayBench: A New Standard for AI Security Evaluation
ZeroDayBench is a paradigm shift in how we evaluate AI security capabilities. Developed by a consortium of security researchers, this benchmark specifically targets the detection and remediation of zero-day vulnerabilities: previously unknown security flaws that attackers exploit before patches become available.
Unlike traditional code generation benchmarks such as HumanEval or CodeBench, which measure general programming capabilities, ZeroDayBench focuses exclusively on security-critical scenarios. The benchmark evaluates models across three critical dimensions: vulnerability detection accuracy, patch correctness, and remediation completeness. Each test presents models with real-world code samples containing subtle security flaws that require deep contextual understanding to identify and fix properly.
What Makes ZeroDayBench Unique
The benchmark’s strength lies in its methodology. Rather than testing against well-documented Common Vulnerabilities and Exposures (CVEs), ZeroDayBench presents novel vulnerability patterns extracted from recent security incidents. These include complex multi-step attack chains, race conditions, and subtle logic flaws that demand sophisticated reasoning capabilities.
Each vulnerability scenario requires models to perform several sequential tasks: initial code analysis, threat vector identification, impact assessment, and finally, generating a complete patch that fixes the security flaw without introducing new vulnerabilities or breaking existing functionality.
The Testing Framework
The evaluation framework employs a rigorous scoring methodology across a 0-10 scale for each dimension. Models face realistic constraints including time limitations and computational resource restrictions that mirror real-world deployment scenarios.
# Example ZeroDayBench vulnerability detection prompt
def process_user_input(user_data, session_id):
"""Process user input and update session state"""
# Potential vulnerability: unchecked buffer overflow
buffer = bytearray(256)
if len(user_data) > 0:
buffer[:len(user_data)] = user_data.encode('utf-8')
# Expected LLM response should identify:
# 1. Buffer overflow risk when user_data > 256 bytes
# 2. Lack of input validation
# 3. Potential memory corruption attack vector
# 4. Provide secure implementation with bounds checking
return update_session(buffer, session_id)The testing protocol measures not only whether models can identify vulnerabilities, but also their ability to generate production-ready patches that maintain code functionality while eliminating security risks. This dual requirement proves particularly challenging for current LLM architectures.
Current State of LLM Security Capabilities
The benchmark results paint a sobering picture of current AI capabilities in cybersecurity. Across the three leading models tested, average detection rates hovered around 27%, with successful patch rates reaching only 31%. Perhaps most concerning, the false positive rate averaged 42%, indicating that models frequently misidentify secure code as vulnerable.
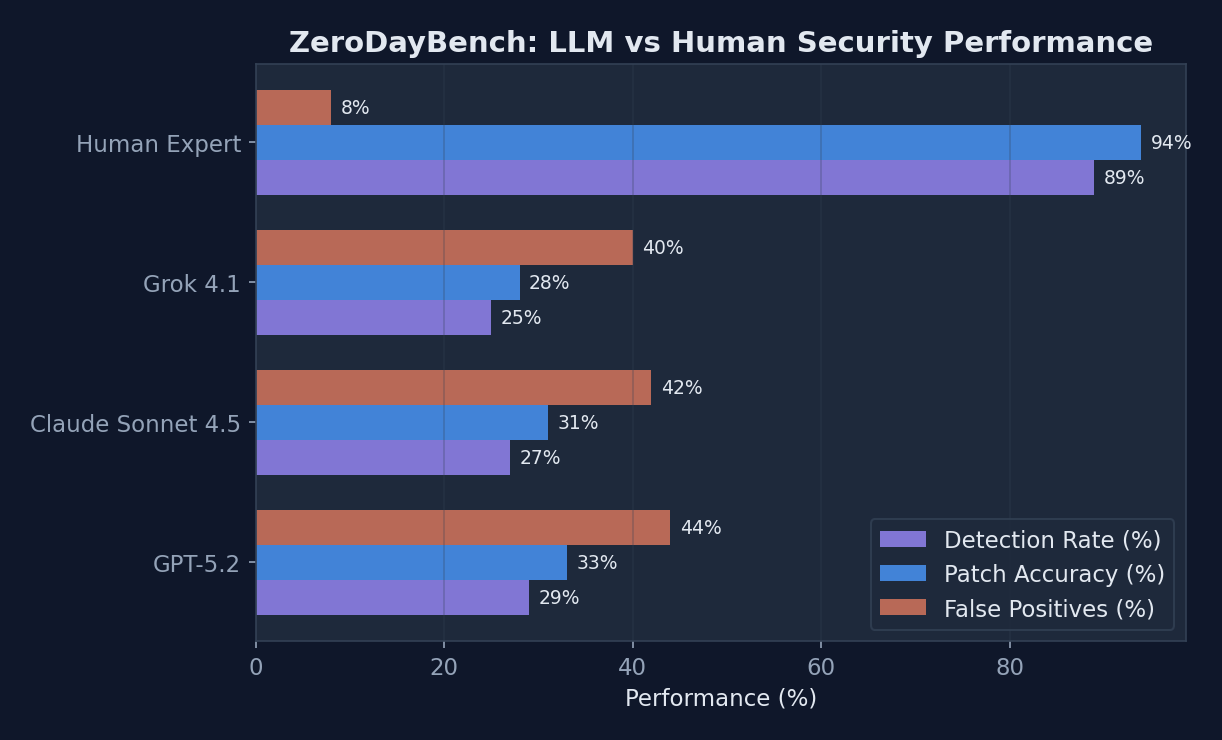 Performance comparison of leading AI models vs. human experts on ZeroDayBench security vulnerability tasks
Performance comparison of leading AI models vs. human experts on ZeroDayBench security vulnerability tasks
The performance disparities between models and vulnerability types reveal important insights about current AI limitations:
| Model | Overall Score | Detection Rate | Patch Accuracy | False Positives | Processing Time (avg) |
|---|---|---|---|---|---|
| GPT-5.2 | 3.2/10 | 29% | 34% | 38% | 45s |
| Claude Sonnet 4.5 | 3.1/10 | 28% | 31% | 41% | 52s |
| Grok 4.1 | 2.9/10 | 24% | 28% | 47% | 38s |
| Human Expert Baseline | 9.1/10 | 89% | 94% | 8% | 180s |
Where LLMs Excel vs. Where They Fail
The benchmark reveals distinct patterns in AI performance across vulnerability categories. Models demonstrated moderate success with buffer overflow detection, achieving 35-40% accuracy rates, likely due to the prevalence of such examples in training data. SQL injection pattern recognition showed higher accuracy at 45-52%, again reflecting common attack vectors well-represented in open-source security datasets.
However, performance collapsed when confronting complex logic flaws and race conditions, where accuracy dropped below 15%. Memory management vulnerabilities produced inconsistent results, with models sometimes identifying obvious flaws while missing subtle pointer arithmetic errors that could lead to exploitation.
The most striking finding involves temporal reasoning challenges. Models consistently failed to understand attack sequences that unfold across multiple function calls or require specific timing conditions. This is particularly problematic for modern security threats that often involve sophisticated multi-stage attacks.
The Human Baseline Problem
Expert security researchers participating in the benchmark achieved 89% detection rates and 94% patch accuracy, establishing a clear performance target for AI systems. Human experts demonstrated superior capabilities in several key areas that current LLMs cannot replicate.
Security professionals employ domain expertise and intuitive pattern recognition to identify subtle anomalies that don’t match obvious vulnerability signatures. They understand the broader context of how applications interact with operating systems, networks, and user behavior, knowledge that helps them anticipate attack vectors that purely code-focused analysis might miss.
The Gap Between AI Capabilities and Cybersecurity Needs
Current LLM architectures face fundamental challenges when applied to security contexts. The statistical nature of language models, trained primarily on pattern recognition and text generation, struggles with the adversarial nature of cybersecurity where attackers actively work to subvert expected behaviors.
The difference between generating functional code and writing secure code requires understanding threat models, attack surfaces, and potential abuse scenarios. These concepts demand causal reasoning about system interactions rather than simple pattern matching against known vulnerability signatures.
Training Data Limitations
Security vulnerabilities remain significantly underrepresented in the massive datasets used to train general-purpose language models. While models encounter countless examples of standard programming patterns, they see relatively few examples of security-critical code contexts, particularly for novel attack vectors that emerge after training data collection.
The adversarial nature of cybersecurity compounds this challenge. Attackers continuously develop new techniques specifically designed to evade existing detection methods, creating a dynamic threat landscape that evolves faster than model training cycles can accommodate. Additionally, proprietary enterprise codebases, where many critical vulnerabilities exist, remain absent from public training datasets.
Reasoning and Causality Challenges
ZeroDayBench exposes critical limitations in how LLMs approach causality and multi-hop reasoning. Security vulnerabilities often result from complex interactions between multiple code components, requiring models to trace execution paths through various conditional branches and function calls.
Current transformer architectures excel at pattern matching but struggle with the systematic analysis required for security evaluation. Understanding that a seemingly innocuous input validation bypass in one function could lead to privilege escalation three function calls later demands reasoning capabilities that current models simply don’t possess.
Implications for Enterprise Security and AI Adoption
Despite these limitations, 68% of security teams already incorporate AI tools into their workflows. This widespread adoption creates a concerning mismatch between AI capabilities and deployment expectations.
The false confidence problem emerges as a critical risk factor. When AI security tools appear sophisticated and provide detailed analysis reports, human operators may develop unwarranted trust in their outputs. The 42% false positive rate observed in ZeroDayBench suggests that relying too heavily on AI recommendations could actually worsen security postures by diverting attention from real threats while missing genuine vulnerabilities.
Practical Deployment Considerations
Organizations implementing AI security tools must carefully design hybrid approaches that leverage AI strengths while compensating for limitations. AI systems can serve effectively as first-pass filters, rapidly scanning large codebases to identify potential areas of concern for human expert review.
However, the integration challenges extend beyond technical capabilities. Existing security workflows, built around human expertise and institutional knowledge, must adapt to incorporate AI insights without compromising thorough analysis. Cost-benefit analysis becomes important as organizations balance AI tool licensing costs against the expense of additional human security expertise required for verification.
The processing time data from ZeroDayBench reveals another practical consideration. While human experts require 180 seconds on average for thorough analysis, AI models complete initial assessments in 38-52 seconds. This speed advantage could prove valuable for rapid triage, provided human verification follows for any flagged issues.
Regulatory and Compliance Implications
The benchmark results carry major implications for AI governance in critical infrastructure sectors. Regulatory frameworks increasingly require organizations to demonstrate due diligence in cybersecurity practices. Relying on AI systems with demonstrated 73% failure rates for critical security decisions could expose organizations to compliance violations and liability concerns.
Insurance providers evaluating cyber risk policies must now consider how AI security tool deployment affects overall risk profiles. The false confidence problem could potentially increase claim frequencies if organizations reduce human security oversight based on inflated confidence in AI capabilities.
The Future of AI in Cybersecurity
Despite current limitations, the research community actively pursues multiple approaches to bridge the capability gap. Specialized security-focused model architectures, trained specifically on vulnerability detection and remediation tasks, show promise for improving performance beyond general-purpose models.
Domain-specific fine-tuning using curated security datasets could address some training data limitations. Reinforcement learning approaches, where models learn from security expert feedback and real-world deployment outcomes, offer pathways to develop more nuanced understanding of security contexts.
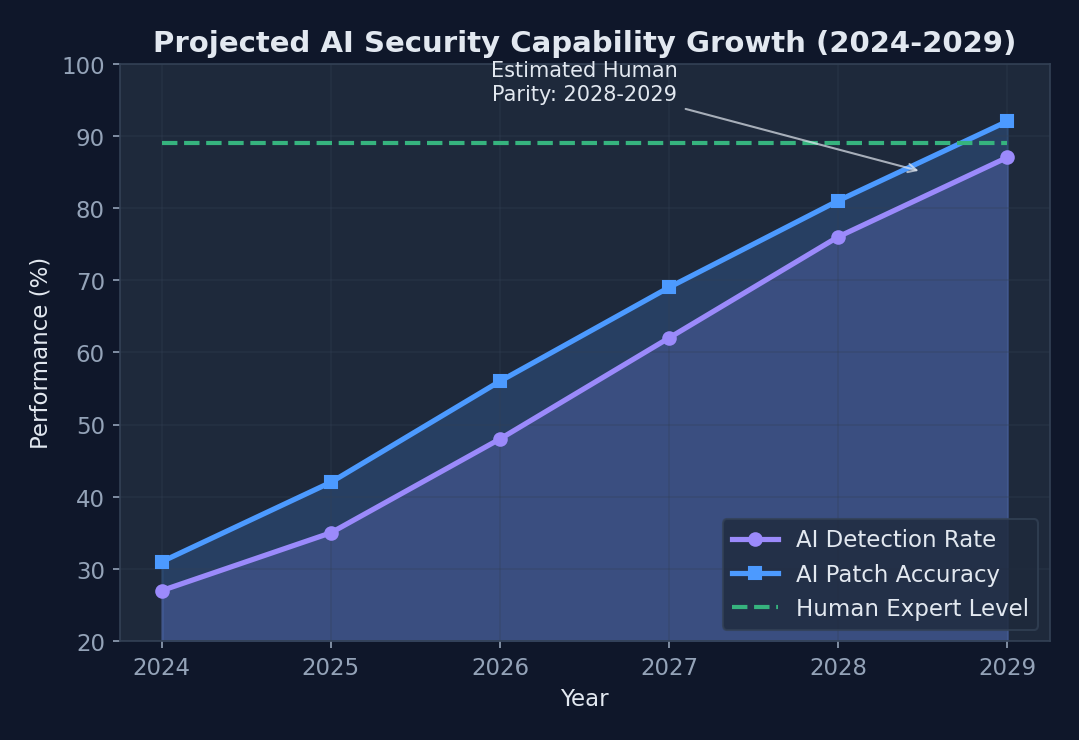 Projected timeline for AI models to reach human-level cybersecurity performance based on current research trends
Projected timeline for AI models to reach human-level cybersecurity performance based on current research trends
Current research trajectories suggest 3-5 years before LLMs achieve human-level security performance, assuming continued advancement in model architectures and training methodologies. However, this timeline depends on overcoming fundamental challenges in reasoning, causality, and adversarial robustness.
Emerging Solutions and Innovations
Multi-agent systems combining different AI specializations show particular promise. Rather than expecting single models to excel at all security tasks, distributed approaches could assign specific vulnerability categories to specialized agents optimized for those contexts.
Integration with formal verification and symbolic reasoning systems could address some of the logical reasoning limitations exposed by ZeroDayBench. Hybrid approaches combining neural networks’ pattern recognition capabilities with symbolic systems’ logical reasoning strengths might achieve better overall performance.
Adversarial training, where models learn to identify vulnerabilities by playing both attacker and defender roles, represents another promising research direction. This approach could help models develop more robust understanding of how security mechanisms can be subverted.
The path forward requires honest acknowledgment of current limitations while continuing to push the boundaries of what’s possible. ZeroDayBench provides the measurement framework needed to track progress and ensure that advances translate into real-world security improvements. As organizations navigate the complex landscape of AI-assisted cybersecurity, success will depend on keeping realistic expectations while strategically using AI where it provides genuine value. The future of cybersecurity lies not in replacing human expertise with AI, but in pairing them so each amplifies the other’s strengths.
Sources
Sponsored
More from this category
More from AI & ML
 R.01
R.01 IBM's Project Debater: The First AI to Successfully Participate in Human Debates
 R.02
R.02 Leveraging AutoML for Faster AI Development: Key Trends and Innovations in 2026
 R.03
R.03 India AI Impact Summit 2026 — Inside the Event That Wants to Redefine India's Role in Global AI
Sponsored
The dispatch
Working notes from
the studio.
A short letter twice a month — what we shipped, what broke, and the AI tools earning their keep.
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored