S.05 · Service
AI Chatbot Development
Embeddable AI chatbots that actually answer the question.
HOW WE WORK
The process we follow.
- 01
Ingest
We crawl your docs, sitemap, MDX, and uploaded PDFs. Embeddings stored in pgvector or Pinecone.
- 02
Tune
Eval set built from your actual support tickets. We benchmark accuracy + latency + cost across providers before picking the default.
- 03
Embed
Single <script> tag on your site. Or self-host the widget. Or build it into your app's UI.
- 04
Iterate
Weekly dashboard of asked-but-failed questions. We patch the knowledge base, retrain, redeploy.
Every engagement is scoped and written down before we start.
Brief us →FIELD NOTES
What clients actually said.
“Finding someone who can actually ship LLM features in production is rare. The studio shipped, then helped me hire a verified builder for the rollout.”

Alex Chen
CEO · Lore Protocol
“Working with CODERCOPS was seamless. They understood the nuances of AI-driven interviews and built a product that feels incredibly human. Our users love the realistic experience.”

Sarah Johnson
Founder · PrepAI
“QueryLytic has democratized data access across our organization. Marketing, sales, and ops teams can now get insights without waiting for engineering. CODERCOPS delivered beyond our expectations.”

Michael Torres
CTO · DataFlow Analytics
BILL OF MATERIALS
The stack we trust.
Models
- Claude (Anthropic)
- GPT-4/5 (OpenAI)
- Gemini (Google)
- Llama (open)
Retrieval
- pgvector
- Pinecone
- Qdrant
- Embedding-cache
Frontend
- Vanilla JS widget (~7KB)
- React component
- Custom UI
Hosting
- Cloudflare Workers
- Vercel Edge
- Self-hosted
Boring choices on purpose. Plain-stack code outlives the consultant. If you have a stack already, we'll meet you there.
What we ship
A chatbot that does one job well: answer questions about your content, accurately, with citations.
Not a personality. Not a “delight” feature. Not a chatty marketing gimmick. A working tool that deflects support tickets, helps users find what they need, and tells you which questions your documentation can’t answer.
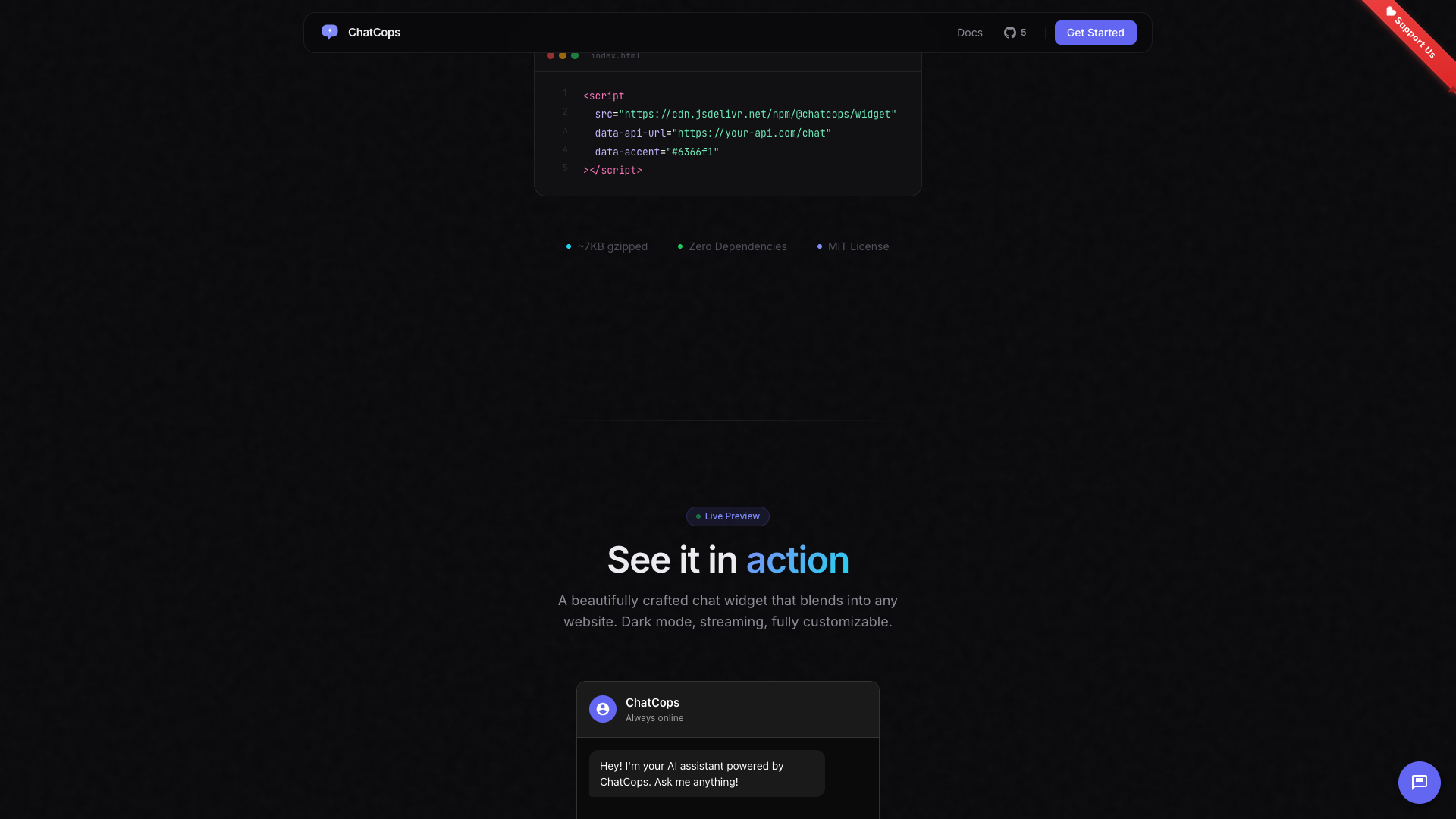
ChatCops — our open-source widget
For teams that want a chatbot up in days, not weeks, we maintain ChatCops — an open-source, embeddable AI chat widget. Drop one <script> tag, point it at your docs, ship.
It’s the foundation we use for most chatbot engagements. Custom builds extend it; simpler installs use it as-is with light theming.
How a custom chatbot is different
A custom chatbot lives inside your product, not on top of it. It knows the user, sees their data, can take actions on their behalf:
- An e-commerce chatbot that knows your order history, can issue refunds, can apply coupons.
- A SaaS copilot that can generate, edit, and save content directly in your product UI.
- A B2B assistant that pulls live data from your warehouse and answers analyst-grade questions.
These are different beasts from a docs chatbot, and we build them differently — agentic, tool-rich, observable end-to-end.
What’s included in every build
- Eval harness. Real questions from your support tickets, scored against expected answers. We can prove the accuracy went up after every prompt change.
- Cost dashboard. Tokens in, tokens out, $ per conversation, per user, per day. No more end-of-month API bill surprises.
- Drift monitoring. When your knowledge base updates, accuracy drops on questions about the new content until we re-embed. We catch this automatically.
- Provider abstraction. Switching from Claude to GPT to Gemini is a config change, not a rewrite. Useful when one provider raises prices or has an outage.
Common questions
Things people ask first.
If a question is in your knowledge base, it cites the source. If not, it says it doesn't know. We disable freeform answers from the model's training data — only your content matters.
Sub-2-second time-to-first-token on most providers, with streaming UI so users see characters appearing immediately.
Yes — tool-calling integrates with Zendesk, Intercom, Slack, or your custom helpdesk. The bot escalates intelligently.
Depends on traffic. Typical small site: $20–80/mo in API costs. Larger sites with 10k+ conversations: $200–500/mo. We provide cost dashboards.
Yes — modern LLMs handle 50+ languages well out of the box. We can ingest a multilingual knowledge base or rely on the model's translation capability.