Cloud & Infrastructure · Cloud Economics
Navigating the AI Storage Tax: Rising NAND & RAM Costs in Cloud Infrastructure
Explore the financial impact of the AI storage tax and the sharp rise in NAND and RAM costs, affecting enterprise IT budgets and cloud infrastructure strategies.

Anurag Verma
12 min read

Sponsored
700% price increases in enterprise storage solutions aren’t science fiction. They’re happening right now as the AI revolution collides with semiconductor supply chains, creating what industry analysts are calling the “AI storage tax.”
This unprecedented surge in storage costs is fundamentally reshaping how enterprises approach cloud infrastructure planning. While organizations rushed to embrace AI capabilities throughout 2024 and 2025, the hidden infrastructure costs are now coming to light in dramatic fashion. The convergence of supply chain constraints, insatiable AI storage demands, and semiconductor manufacturing bottlenecks has created a perfect storm that’s forcing CIOs and CFOs to completely recalibrate their technology budgets.
The AI Storage Tax Explained: When Compute Demand Breaks Economics
The AI storage tax represents the premium enterprises now pay for storage infrastructure driven by artificial intelligence workloads. Unlike traditional enterprise applications that follow predictable storage patterns, AI systems demand massive, high-performance storage resources that operate at scales previously reserved for hyperscale cloud providers.
Recent market analysis reveals a staggering 25% NAND wafer cost increase within just the past month, with industry forecasts projecting a 130% surge in DRAM and SSD prices by the end of 2026. These aren’t gradual market adjustments. They represent fundamental shifts in supply and demand dynamics that are cascading through the entire technology stack.
AI workloads differ fundamentally from traditional computing in their storage requirements. While a typical enterprise database might require consistent, moderate IOPS with predictable capacity growth, AI training workloads demand massive sequential read/write operations, often consuming terabytes of data per training session. Large Language Models like GPT-4 and Claude require not just initial training datasets measured in petabytes, but also ongoing storage for model checkpoints, fine-tuning data, and inference caching.
The cascade effect flows directly from chip manufacturing through cloud providers to enterprise customers. When Taiwan Semiconductor Manufacturing Company (TSMC) prioritizes AI chip production over storage components, the resulting storage chip shortage drives up prices for memory manufacturers like Micron Technology and SK Hynix. These increased costs flow through to storage system manufacturers like Pure Storage and NetApp, ultimately landing on enterprise balance sheets as dramatically higher cloud storage bills.
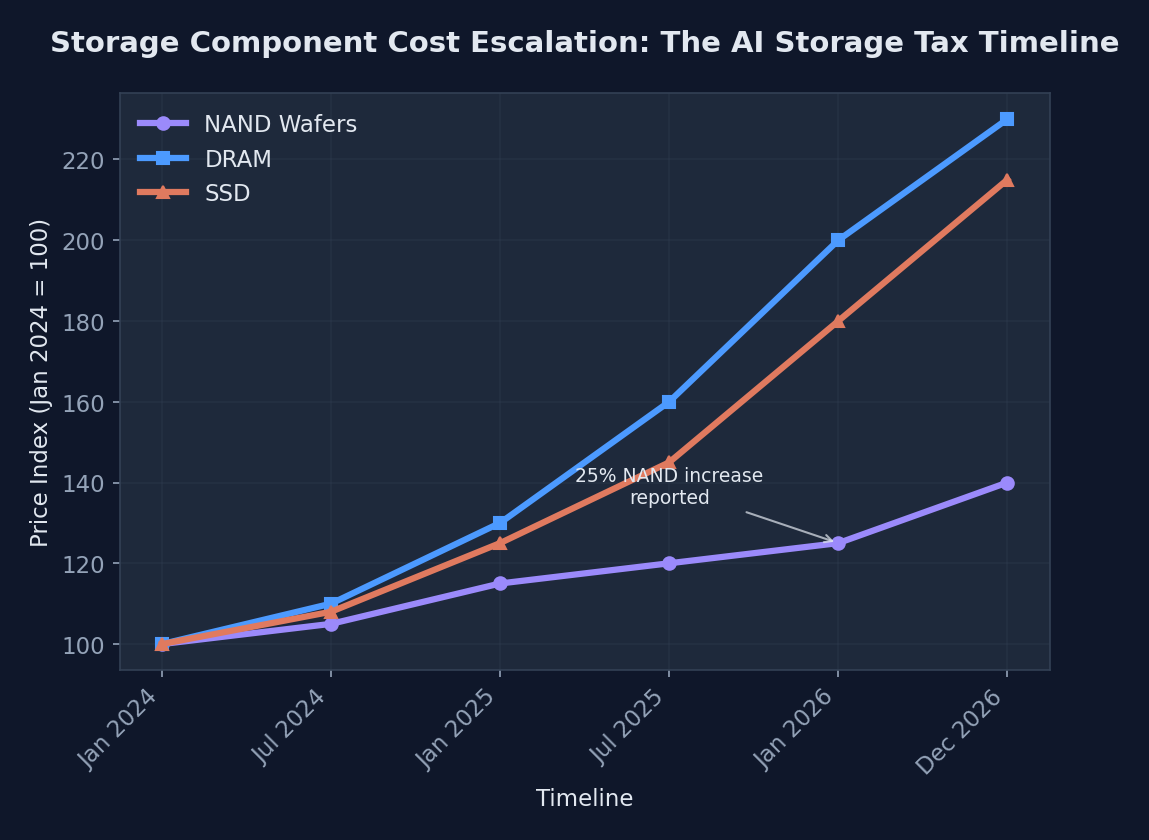 The projection shows exponential cost increases across all storage technologies, with SSD prices leading the surge due to AI workload demands
The projection shows exponential cost increases across all storage technologies, with SSD prices leading the surge due to AI workload demands
The Perfect Storm: Supply Chain Pressures Meet AI Hunger
Silicon Shortage Meets Silicon Valley
The semiconductor manufacturing landscape has become a critical chokepoint for the entire AI infrastructure ecosystem. TSMC and Samsung, which control approximately 75% of global advanced chip manufacturing capacity, are operating at maximum utilization while facing unprecedented demand from both AI chip designers and traditional storage component manufacturers.
Manufacturing bottlenecks have intensified as foundries prioritize high-margin AI processors over commodity storage chips. NVIDIA’s ongoing orders for H100 and H200 AI chips consume significant foundry capacity, creating knock-on effects for NAND flash and DRAM production. This prioritization reflects economic realities: AI chips command margins of 60-70% compared to 15-20% for storage components.
Geopolitical factors compound these technical constraints. Export restrictions on advanced semiconductor equipment to China have reduced global manufacturing capacity, while ongoing tensions over Taiwan create supply chain uncertainty. The CHIPS and Science Act in the United States and similar initiatives in Europe are driving domestic manufacturing investments, but new fabs won’t reach full production until 2027-2028.
AI’s Insatiable Appetite for Storage
AI workloads consume storage resources in patterns that traditional enterprise infrastructure wasn’t designed to handle. Large Language Model training requires simultaneous access to massive datasets. Meta’s LLaMA 2 training used over 2 trillion tokens, requiring approximately 10TB of storage just for the training data, not including model checkpoints and intermediate results.
Computer vision applications present different but equally demanding requirements. Tesla’s Full Self-Driving neural networks process approximately 160GB of camera and sensor data per hour during active learning phases. Multiplied across millions of vehicles, these storage requirements dwarf traditional automotive industry data needs by several orders of magnitude.
The distinction between AI training and inference workloads creates complex storage optimization challenges. Training workloads require massive sequential I/O for dataset access, while inference workloads demand low-latency random access to model parameters. This dual requirement forces organizations to provision for peak demands across both use cases.
| Workload Type | Storage Requirement (TB) | IOPS Demand | Cost per TB | Monthly Cost Impact |
|---|---|---|---|---|
| Traditional Database | 5-50 | 1,000-10,000 | $0.08 | $400-4,000 |
| Web Application | 1-10 | 500-5,000 | $0.06 | $60-600 |
| Large Language Model Training | 500-5,000 | 100,000-1M | $0.25 | $125,000-1.25M |
| Computer Vision Processing | 100-1,000 | 50,000-500K | $0.20 | $20,000-200,000 |
| Real-time AI Inference | 10-100 | 10,000-100K | $0.15 | $1,500-15,000 |
| Hybrid AI Workload | 200-2,000 | 25,000-250K | $0.18 | $36,000-360,000 |
Cloud Giants Feel the Squeeze: How AWS, Azure, and GCP Are Responding
Price Pass-Through Strategies
Major cloud providers are implementing sophisticated pricing strategies to manage the AI storage tax while maintaining competitive positioning. Amazon Web Services introduced new EBS gp4 volumes in late 2025, specifically designed for AI workloads with premium pricing that reflects the underlying cost structure: 30% higher than traditional gp3 volumes but with 40% better performance for sequential AI workloads.
Microsoft Azure has taken a different approach with their Ultra Disk v2 offerings, implementing dynamic pricing based on actual IOPS consumption rather than provisioned capacity. This model shifts cost optimization responsibility to customers while providing more granular cost control for AI applications that have variable storage performance requirements.
Google Cloud Platform introduced Hyperdisk Extreme with tiered pricing that explicitly acknowledges the AI storage premium. Their pricing model includes a base storage cost plus performance tiers, with AI-optimized configurations carrying a 25-35% premium over traditional enterprise storage classes.
Infrastructure Innovation as Cost Mitigation
Cloud providers are investing heavily in storage architecture innovations to offset rising component costs through efficiency gains. AWS’s Graviton3 processors include specialized instructions for storage compression, enabling 15-20% storage capacity savings for AI datasets through hardware-accelerated compression.
Edge computing strategies are emerging as critical cost mitigation tools. Azure’s Edge Zones and AWS Local Zones reduce central storage demands by processing AI inference workloads closer to data sources. This distributed approach can reduce primary storage costs by 30-40% for real-time AI applications.
Smart caching technologies specifically designed for AI workloads are showing promising results. Google’s Cloud Storage implements intelligent prefetching for training datasets, reducing actual storage IOPS requirements by predicting data access patterns. Early deployments show 25% reductions in storage performance costs for iterative training workloads.
import boto3
import json
from datetime import datetime, timedelta
class AIStorageOptimizer:
def __init__(self, region='us-east-1'):
self.s3_client = boto3.client('s3', region_name=region)
self.cloudwatch = boto3.client('cloudwatch', region_name=region)
def optimize_ai_dataset_lifecycle(self, bucket_name, dataset_prefix):
"""
Implement intelligent lifecycle management for AI datasets
based on access patterns and training schedules
"""
# Analyze access patterns for the last 30 days
access_patterns = self.analyze_access_patterns(bucket_name, dataset_prefix)
lifecycle_rules = []
# Training datasets: Move to IA after 30 days, Glacier after 90 days
training_rule = {
'ID': 'AITrainingDataLifecycle',
'Status': 'Enabled',
'Filter': {'Prefix': f'{dataset_prefix}/training/'},
'Transitions': [
{
'Days': 30,
'StorageClass': 'STANDARD_IA'
},
{
'Days': 90,
'StorageClass': 'GLACIER'
}
]
}
# Model checkpoints: Keep active checkpoints in Standard, archive old ones
checkpoint_rule = {
'ID': 'AICheckpointLifecycle',
'Status': 'Enabled',
'Filter': {'Prefix': f'{dataset_prefix}/checkpoints/'},
'Transitions': [
{
'Days': 7,
'StorageClass': 'STANDARD_IA'
},
{
'Days': 30,
'StorageClass': 'DEEP_ARCHIVE'
}
]
}
lifecycle_rules.extend([training_rule, checkpoint_rule])
# Apply lifecycle configuration
lifecycle_config = {'Rules': lifecycle_rules}
try:
self.s3_client.put_bucket_lifecycle_configuration(
Bucket=bucket_name,
LifecycleConfiguration=lifecycle_config
)
# Calculate potential cost savings
savings = self.calculate_lifecycle_savings(bucket_name, lifecycle_rules)
return {
'status': 'success',
'rules_applied': len(lifecycle_rules),
'estimated_monthly_savings': savings
}
except Exception as e:
return {'status': 'error', 'message': str(e)}
def analyze_access_patterns(self, bucket_name, prefix):
"""Analyze S3 access patterns for intelligent tiering decisions"""
end_time = datetime.utcnow()
start_time = end_time - timedelta(days=30)
# Get CloudWatch metrics for S3 requests
response = self.cloudwatch.get_metric_statistics(
Namespace='AWS/S3',
MetricName='NumberOfObjects',
Dimensions=[
{'Name': 'BucketName', 'Value': bucket_name}
],
StartTime=start_time,
EndTime=end_time,
Period=86400, # Daily aggregation
Statistics=['Average']
)
return response['Datapoints']
def calculate_lifecycle_savings(self, bucket_name, lifecycle_rules):
"""Calculate estimated cost savings from lifecycle policies"""
# Simplified cost calculation based on storage class pricing
standard_cost = 0.023 # per GB per month
ia_cost = 0.0125 # per GB per month
glacier_cost = 0.004 # per GB per month
# Estimate bucket size and calculate savings
# This is a simplified calculation for demonstration
estimated_size_gb = 10000 # 10TB dataset
savings_ia = (standard_cost - ia_cost) * estimated_size_gb * 0.7 # 70% moves to IA
savings_glacier = (ia_cost - glacier_cost) * estimated_size_gb * 0.5 # 50% moves to Glacier
total_monthly_savings = savings_ia + savings_glacier
return round(total_monthly_savings, 2)
# Usage example
optimizer = AIStorageOptimizer()
result = optimizer.optimize_ai_dataset_lifecycle(
bucket_name='ai-training-datasets',
dataset_prefix='llm-training'
)
print(f"Optimization result: {result}")Enterprise Impact: Budgets Under Siege
The AI storage tax is forcing enterprise technology leaders to fundamentally reconsider their infrastructure strategies and budget planning processes. Fortune 500 companies report storage cost increases of 40-60% year-over-year, with AI-heavy organizations seeing even more dramatic impacts.
A major financial services firm implementing fraud detection AI saw their monthly AWS S3 bills increase from $50,000 to $180,000 within six months, driven primarily by the storage requirements for real-time transaction analysis and model training data. The company’s CFO noted that storage costs had become the second-largest component of their AI infrastructure spending, behind only compute resources.
Manufacturing companies deploying computer vision for quality control face particularly acute challenges. General Electric’s digital factory initiative requires storing high-resolution images from thousands of production line cameras, generating approximately 2TB of new data daily per factory. With traditional storage pricing models, this data would cost roughly $1,500 monthly per factory for basic storage. Under the AI storage tax, the same storage requirements now cost $2,400-2,700 monthly.
The impact on AI project ROI calculations is forcing many organizations to delay or restructure planned initiatives. A pharmaceutical company’s drug discovery AI project originally budgeted $2 million annually for infrastructure now faces projected costs of $3.2 million, primarily due to storage cost inflation. The company has responded by implementing more aggressive data lifecycle management and exploring hybrid cloud architectures.
CFOs are implementing new budget planning processes that account for storage cost volatility. Traditional three-year technology budgets assumed relatively stable storage costs with predictable growth patterns. Current planning cycles include 20-30% annual variability buffers specifically for storage costs, fundamentally changing how organizations approach technology investment decisions.
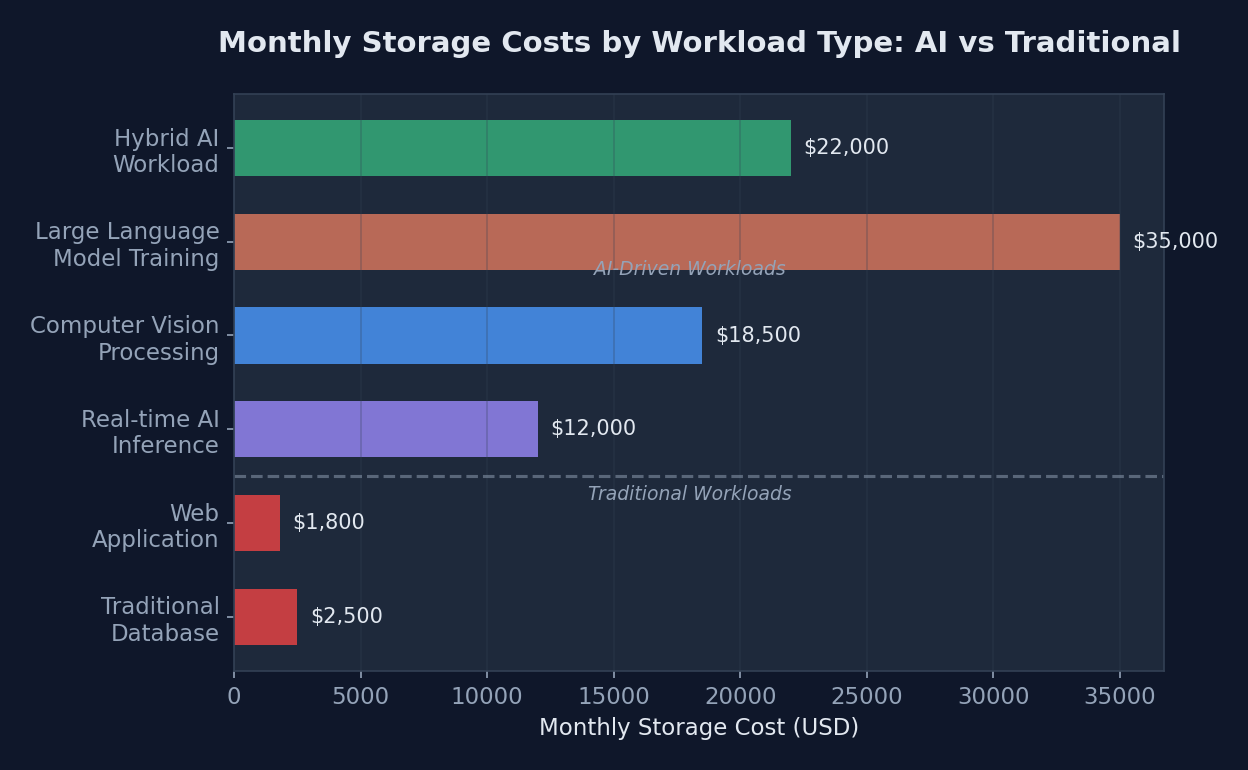 The stark cost differential between AI and traditional workloads illustrates why enterprises are scrambling to optimize their storage strategies
The stark cost differential between AI and traditional workloads illustrates why enterprises are scrambling to optimize their storage strategies
Strategic Responses: Navigating the New Reality
Cost Optimization Techniques
Forward-thinking organizations are implementing sophisticated multi-cloud strategies to exploit storage pricing arbitrage opportunities. Netflix pioneered this approach by distributing their AI recommendation training data across AWS, Google Cloud, and Azure based on real-time pricing analysis. Their automated system moves datasets between providers when price differentials exceed 15%, resulting in 22% average storage cost reductions.
Data lifecycle management has evolved from a cost optimization best practice to a survival strategy. Advanced AI organizations are implementing semantic lifecycle management that considers not just data age, but model accuracy impact and retraining frequency. A computer vision company reduced storage costs by 45% by automatically archiving training images that contribute less than 2% to model accuracy improvements.
Intelligent archiving systems specifically designed for AI workloads are emerging as critical cost management tools. OpenAI’s approach involves compressing and archiving model checkpoints using AI-optimized compression algorithms, achieving 60% storage reduction while maintaining the ability to resume training from archived states within 10 minutes.
Future-Proofing Storage Architecture
Organizations are investing in storage technologies that provide flexibility for uncertain cost environments. Software-defined storage solutions from vendors like Red Hat Ceph and VMware vSAN allow dynamic allocation between high-performance and cost-optimized storage based on workload requirements and current pricing.
Edge computing architectures are becoming essential for managing storage costs in AI applications. Autonomous vehicle companies like Waymo process initial sensor data at edge nodes, reducing the amount of raw data transmitted to central storage systems by 80%. This distributed processing approach cuts primary storage requirements while improving real-time performance.
Emerging storage technologies offer potential long-term solutions to the AI storage crisis. DNA storage companies like Catalog and Twist Bioscience are developing systems that could store petabytes of AI training data at dramatically lower costs than traditional storage, though read/write speeds currently limit applications to archival use cases.
The Road Ahead: Long-term Implications and Market Predictions
Industry analysts predict the AI storage tax will persist through 2027, with potential market corrections beginning in 2028 as new semiconductor manufacturing capacity comes online. Gartner projects that storage costs will stabilize at levels 40-50% higher than pre-AI boom pricing, reflecting permanently higher performance and capacity requirements.
The storage cost crisis is already reshaping AI development priorities. Companies are investing heavily in model compression and efficient architecture research to reduce storage footprints. Google’s recent Gemma models achieve comparable performance to larger models while requiring 60% less storage for training and inference.
Supply chain diversification initiatives are gaining momentum across the industry. The U.S. Department of Commerce estimates that domestic semiconductor manufacturing capacity will increase by 200% by 2030, potentially reducing supply chain concentration risks that contributed to current price volatility.
Government and industry initiatives are addressing long-term supply chain vulnerabilities. The European Union’s Chips Act allocates €43 billion for semiconductor manufacturing capacity, while Japan’s partnerships with TSMC aim to establish alternative manufacturing nodes. These investments may provide relief from storage cost pressures by 2028-2029.
The AI storage tax ultimately threatens to create a two-tier AI economy where only well-funded organizations can afford cutting-edge AI capabilities. This digital divide risk is driving policy discussions about AI infrastructure subsidies and public cloud initiatives to ensure broader access to AI technologies.
As we move forward, the organizations that thrive will be those that treat storage cost management as a core competency rather than an operational detail. The AI revolution will continue, but its infrastructure costs will fundamentally reshape how we build, deploy, and scale intelligent systems. The storage tax isn’t just a temporary market disruption. It’s a permanent shift that will define the next phase of AI development and deployment strategies.
Sources
Sponsored
More from this category
More from Cloud & Infrastructure
 R.01
R.01 Post-Cloud Era: Embracing Serverless Edge Computing for Optimized Performance
 R.02
R.02 The Cloudflare Outage of February 2026 — A Postmortem and the Architecture Lessons Nobody Tells You
R.03 Platform Engineering in 2026: The Internal Developer Platform Maturity Report
Sponsored
The dispatch
Working notes from
the studio.
A short letter twice a month — what we shipped, what broke, and the AI tools earning their keep.
Discussion
Join the conversation.
Comments are powered by GitHub Discussions. Sign in with your GitHub account to leave a comment.
Sponsored